

We often hear about Google, Facebook or some other tech giant pioneering a new facial recognition tool, but which is actually best?
A new study into how various facial recognition software performs has found that actual effectiveness plummets as test sample sizes grow.
University of Washington researchers claim most AI tests are performed on datasets of just a few thousand images – far below the number of Irish fans in Stade Pierre-Mauroy for Ireland’s 1-0 win over Italy on Wednesday night.
So, considering the pool is actually quite small, why not challenge them with a dataset in the millions?

What happens?
“What happens if you lose your phone in a train station in Amsterdam and someone tries to steal it?” said Kemelmacher-Shlizerman, who co-leads the UW Graphics and Imaging Laboratory (GRAIL.) “I’d want certainty that my phone can correctly identify me out of a million people — or 7bn — not just 10,000 or so.”
Called the MegaFace Challenge, researchers pitted several AIs against scale. First testing them against modest datasets before rolling them out onto 1m images from Flickr – representing 690,572 unique images.
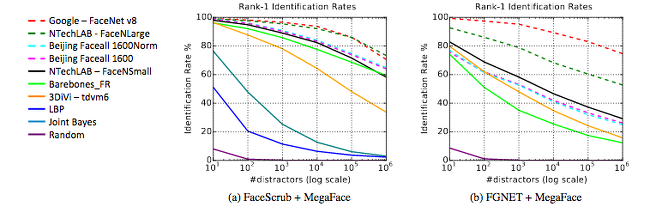
The findings, which are ongoing, the test updating until a presentation at the end of the month, show that Google’s FaceNet showed the strongest performance on one test, while Russia’s N-TechLab topped the bill on another.
However, the performances dropped off as the datasets expanded. FaceNet dropped from near-perfect accuracy when confronted with a smaller number of images to 75pc on the 1m-person test. N-TechLab dropped to 73pc.
Age-old question
A pretty interesting element to the research is how the team investigated the actual algorithms behind the AIs. They did this to find out how software performs when challenged with just one image of someone, from perhaps years ago, before trying to find their present-day face among the hundreds of thousands of options.
In general, those AIs that “learned” how to find images from the larger databases performed better than those that did not, though the Chinese SIAT MMLab proved an anomaly in that regard, outperforming most.

Solving a problem like that of ageing targets is an interesting challenge, via University of Washington
Social network
“Having diversity in the data, such as the intricate identity cues found across more than 500,000 unique individuals, can increase algorithm performance by providing examples of situations not yet seen,” said Aaron Nech, a UW computer science and engineering master’s student working on the training dataset.
Social media is driving a lot of today’s image recognition developments. That’s largely because social media itself is entirely structured through big data, with each operator quickly becoming experts in this field.
Google was the first tech giant to show its hand in this regard, playing its part in two groundbreaking papers a few years back that showed us software that could ‘read’ images.
Since then, everybody has gotten involved.
Main facial recognition image via Shutterstock





